2018-10-31 阅读量: 920

集群是类似的数据子集。聚类(也称为无监督学习)是将数据集划分为组的过程,使得每个组的成员尽可能彼此相似(接近),并且不同的组彼此尽可能不同(远)。群集可以发现数据集中以前未检测到的关系。群集分析有很多应用。例如,在商业中,聚类分析可用于发现和表征客户细分市场以用于营销目的,并且在生物学中,它可用于根据其特征对植物和动物进行分类。 两组主要的聚类算法是:
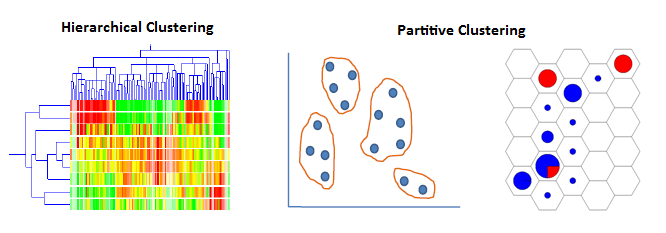
一个好的聚类方法要求是:
聚类中的一个重要问题是如何确定两个对象之间的相似性,以便聚类可以由聚类内具有高相似性和聚类之间的低相似性的对象形成。通常,为了测量对象之间的相似性或不相似性,使用诸如欧几里得,曼哈顿和明科夫斯基的距离度量。距离函数为彼此更相似的对象对返回较低的值。





三个资料Q群下载不了也转发不了,先放这里Fine_tuning.zipLangChain.zipdata_clear.rar
