本篇目录
一、表结构的基本特性

二、SQL语言的书写规则

三、定义语言 DDL
I、数据库的创、删、选、查
•show databases; 【查看数据库】 •create database 数据库名称; 【创建数据库】 •use 数据库名称; 【选择使用数据库】 •drop database 数据库名称; 【删除数据库】
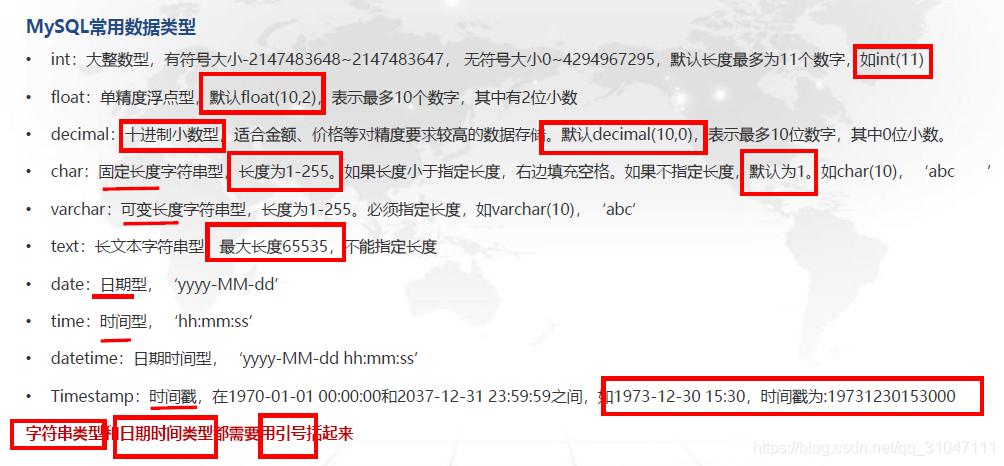
II、常用数据类型
III、约束
主键约束:非空不重复

唯一约束:不能重复

外键约束:与主键相对应,外键字段的值域必须是对应主键值域的子集

自动增长约束:自动增长

非空约束:不能为空

默认约束:当未显式初始化字段值,自动填充默认值

IV、数据表结构的创、增、删、选、查、改
•create table 表名(…); 【创建数据表】 •show tables; 【查看当前数据库中所有表】 •desc 表名; 【查看表结构】 •drop table 表名; 【删除数据表】 •alter table 原表名 rename 新表名; 【修改表名】 •alter table 表名 change 原字段名 新字段名 数据类型; 【修改字段名】 •alter table 表名 modify 字段名 新数据类型; 【修改字段类型】 •alter table 表名 add 新字段名 数据类型; 【添加字段】 •alter table 表名 modify 字段名 数据类型 first; 【修改字段的排列位置至第一列】 • alter table 表名 modify 要排序的字段名 数据类型 after 参照字段; 【修改字段的排列位置至参照字段之后】 •alter table 表名 drop 字段名; 【删除字段】
四、操作语言 DML
I、 插入操作
•insert into 表名(字段名1[,字段名2,...]) values(字段值 1[,字段值 2,...]); 【指定字段名插入】 •insert into 表名 values(字段值 1[,字段值 2,...]); 【插入所有字段的值,需要为表中每一个字段指定值,且值的顺序须和数据表中字段顺序相同】 •load data infile '文件路径.csv' 【批量导入数据】into table 表名 fields terminated by ',' ignore 1 lines;
II、 更新操作
update 表名 set 字段名1=字段值1[, 字段名2=字段值2[,…]][ where 更新条件];
III、 删除操作
•delete from 表名[ where 删除条件];•truncate 表名; 【与delete from 表名一样,都是删除表中全部数据,保留表结构)】
五、查询语言 DQL
I、SQL语句的执行顺序

II、单表查询
•select * from 表名; 【全表查询】 •select 字段1[,字段2,…] from 表名; 【查询指定列】 •select 字段名 as 列别名 from 原表名 [as ]表别名; 【别名的设置】 •select distinct 字段名 from 表名; 【查询不重复的记录】 •select 字段1[,字段2,…] from 表名 where 查询条件; 【条件查询】 •select 字段1[,字段2,…] from 表名 where 空值字段 is[ not] null; 【空值查询】 •select 字段1[,字段2,…] from 表名 where 字符串字段[ not] like 通配符; 【模糊查询,其中'%'匹配多个字符,'_'匹配一个字符】 •select 字段1[,字段2,…] from 表名 order by 字段1[ 排序方向,字段2 排序方向,…]; 【查询结果排序,asc升序(默认),desc降序,注意:多字段排序时,先按第一个字段排序,第一个字段值相同时再按第二个字段排序】 •select 字段1[,字段2,…] from 表名 limit [偏移量,] 行数; 【限制查询结果数量,注意:初始记录行的偏移量是0】 •select 字段1[,字段2,…] from 表名[ where 查询条件] group by 分组字段1[,分组字段2,…]; 【分组查询,将查询结果按照一个或多个字段进行分组,字段值相同的为一组,对每个组进行聚合计算】 •select 字段1[,字段2,…] from 表名[ where 查询条件][ group by 分组字段1[,分组字段2,…]] having 筛选条件; 【分组后筛选】
III、多表查询
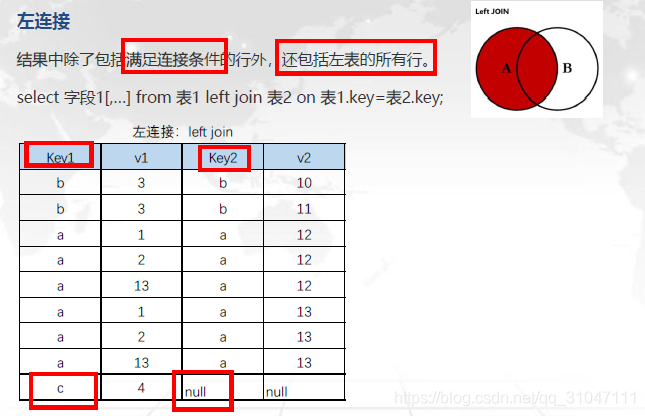
左连接
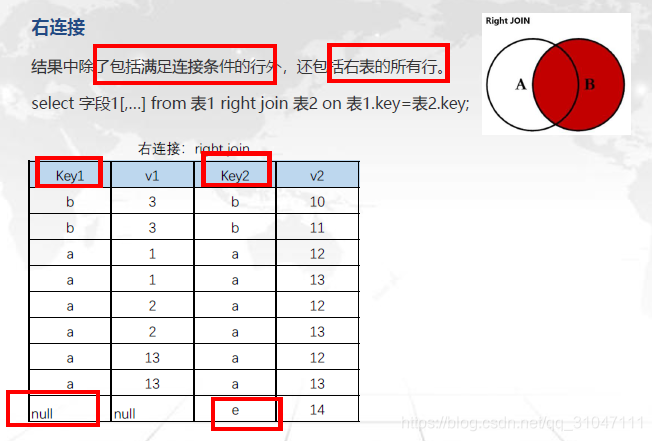
右连接
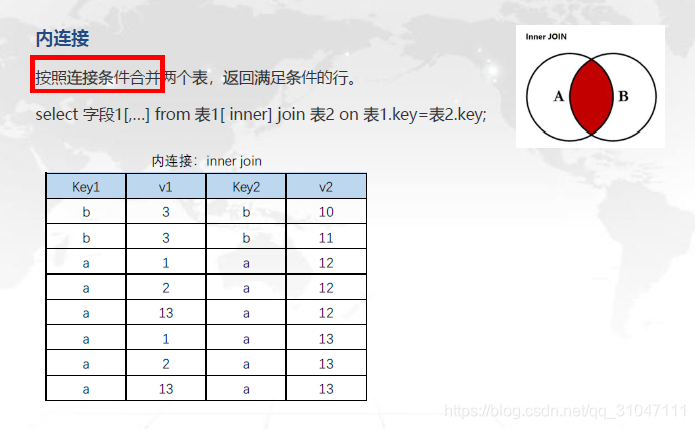
内连接
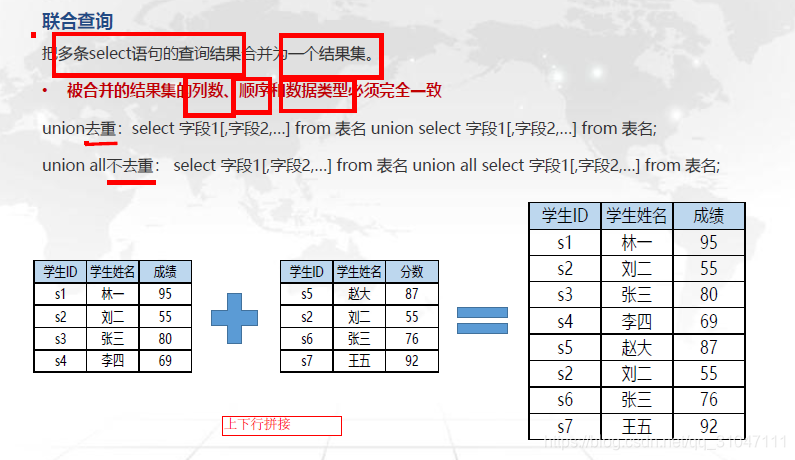
IV、联合查询
V、子查询
出现在select的子查询
select sal/(select count(sal) from emp) as avg_salfrom emp;
出现在from的子查询
select *from emp left join ( select * from emp ) as t1 on emp.id = t1.id;
出现在where的子查询
1.select *from empwhere user_id in ( select user_id from emp where sal > 3000 ); 【使用关键字in或者not in】2.select *from empwhere user_id any ( select user_id from emp where sal > 3000 ); 【使用关键字any】3.select *from empwhere user_id all ( select user_id from emp where sal > 3000 ); 【使用关键字all】
VI、常用函数
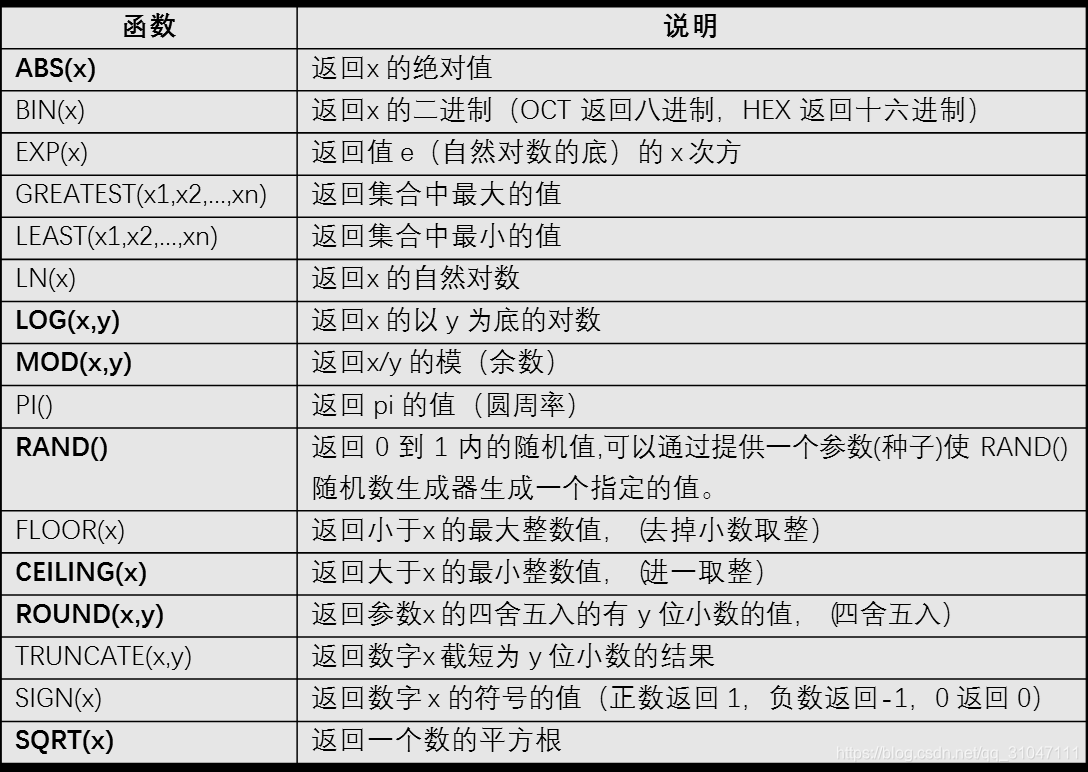
数学函数
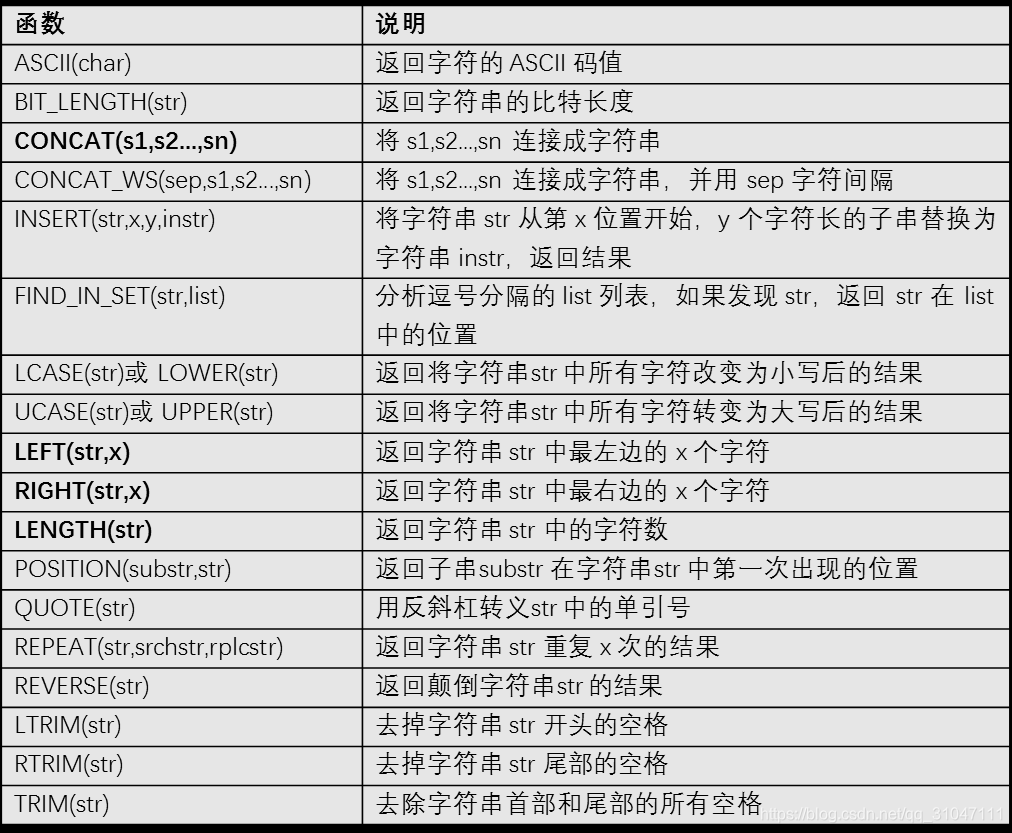
字符串函数
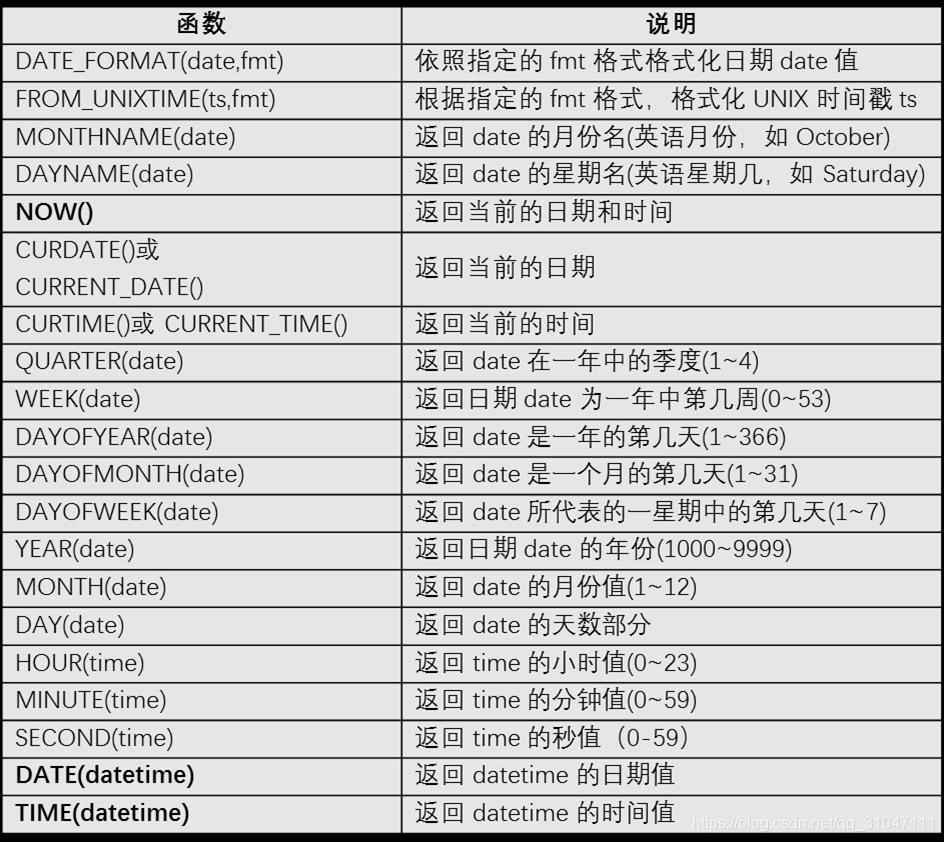
日期时间函数